






1. 強化学習とは??
強化学習(Reinforcement Learning: RL)とは、エージェント(AI)が環境との試行錯誤を通じて、得られる「報酬(Reward)」を最大化するように行動を選択していく学習手法です。
人間が自転車の乗り方を覚えるとき、最初から完璧な物理方程式を解くわけではありません。「右に傾いたら左にハンドルを切る」といった試行を繰り返し、転ばなかった(報酬を得た)経験を積み重ねて上達します。強化学習はこのプロセスをアルゴリズム化したものです。
2. 強化学習のアルゴリズム
強化学習の意思決定を数理的に定義するのがマルコフ決定過程(Markov Decision Process: MDP)です。この枠組みでは、エージェントの目的を「単発の報酬」ではなく、将来にわたる報酬の合計である収益()の最大化として定義します。
2.1. 収益と割引率の定義
収益は以下の式で定義されます。
ここで、は各時刻の報酬、は割引率()です。
- による挙動制御: 割引率は「未来の不確実性」や「時間効率」を表現します。例えば、一秒後に成功すれば 1ポイント、二秒後なら0.9ポイントという減衰を設定することで、ロボットに「無駄な動きを省き、最短時間でタスクを完了せよ」というインセンティブを与えることができます。
- 性格の設計:を小さくすれば「目先の利益を追う短期型」、1に近づければ「最終的な成功を見据える長期型」へとエージェントの性格を制御できます。
2.2. 状態価値 と方策
MDPのゴールは、この収益の期待値を最大化する方策を見つけ出すことです。そこで重要になるのが、状態価値です。とは、現在の状態における将来得られるであろうの期待値のことで、ロボットはこれが最大となるような方策を実行しようとするわけです。
例えば、以下の図のように、①にいる時に報酬1が得られ、ロボットがはじめに③にいるとし、左右のエリアにそれぞれ1/2で動くとし、一回移動するごとの割引率を0.9とします。

この時、4回動いた後までを考慮すると、得られる収益は以下のようになって
次に②に動いた場合
1/2の確率でその次に①に動く、または1/8の確率で次の3回で③→②→①と動いた場合に収益を得ることができて、この場合の収益の期待値は、割引率が0.9なので、
となります。
次に④に動いた場合
1/8の確率で次の3回で③→②→①と動いた場合に収益を得ることができて、この場合の収益の期待値は、割引率が0.9なので、
となります。
よって、ロボットが取るべき方策は次に②に動くとなります。
これが最大となるような行動を行うように方策を更新し続けることが、強化学習によってAIが求める動きを学習する仕組みです。
3. 報酬設計
与える報酬の定義によってAIの挙動が変わることは2章で解説しましたが、この報酬設計を実際にうまく行うことは容易ではありません。
なぜなら、AIは報酬を最大化することに極めて忠実なため、しばしば人間の意図を裏切る報酬ハックを起こすからです。
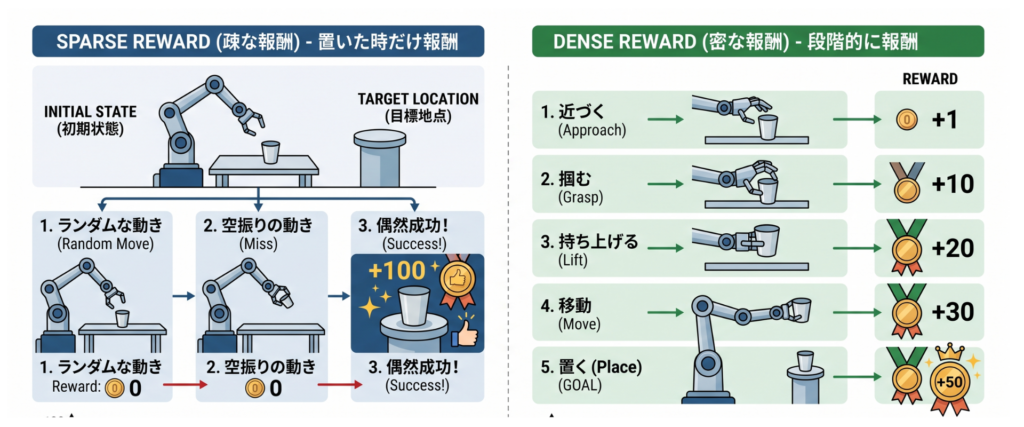
報酬設計には求める挙動を再現した場合にのみ報酬を与える疎な報酬設計と、段階的に報酬を与える密な報酬設計があります。それぞれの特徴は以下の図の通りです。
| 手法 | 設計イメージ | メリット | デメリット(リスク) |
| 疎な報酬 | 成功時にのみ加点 (例: 運べたら+100) | 人間のバイアスを排除した最適な動きを自律発見できる | 学習の停滞。偶然成功するまで報酬がゼロのため、学習が始まらない |
| 密な報酬 | 過程に細かく加点 (例: 近づけば+1) | 学習速度が圧倒的に早い。エンジニアが学習の方向を制御できる | 報酬ハック。正解の挙動を行う代わりに過程の挙動を行うことで点数を稼ぐ |
以下の図のように、疎な報酬の例では、コップを目標地点に置いた時のみに報酬を与えるのに対して、密な報酬ではコップを持ち上げる、持つ、移動させることそれぞれに報酬を与えます。
4. 強化学習の弱点
強化学習(RL)は、試行錯誤を通じて最適な動きを自律的に獲得できる強力な手法ですが、フィジカルAIとして実社会に実装する際には、深刻な弱点がいくつか存在します。
4.1. 膨大な試行回数
強化学習は本質的に「数打ちゃ当たる」という探索に基づいています。しかし、複雑な動作をゼロから習得するには数億ステップのデータが必要になることも珍しくありません。
また、報酬が遠すぎると、いくら時間をかけても正解に辿り着かない場合も多いです。
4.2. 報酬ハック
3章でも触れた通り、人間が意図した通りの動きをAIに「得点」として伝えるのは至難の業です。報酬設計が不適切だと、AIは「人間が望む動き」ではなく「スコアを稼ぐバグのような動き」を見つけ出します。
例えば、「コップを運ぶ」タスクで「手に力を入れる」ことに報酬を与えすぎると、コップを運ばずにその場で全力で指を握りしめ、報酬だけを稼ごうとするといった挙動を起こします。
4.3. 弱点を補う方法
0からロボットを強化学習しようとすると上記したような問題が発生します。そのため、事前に以下に挙げるような方法である程度の動きをロボットに覚えさせたのちに、強化学習を行う場合が多いです。
①イミテーション学習(IL)による初期化
強化学習最大の弱点である「膨大な試行回数」を解決するのがイミテーション学習です。まず人間の操作データをお手本として学習させることで、AIに筋の良い初期動作を叩き込みます。これにより、砂漠で針を探すようなランダムな探索をスキップし、学習時間を劇的に短縮することが可能になります。
②VLA(Vision-Language-Action)による指針
報酬ハックは、AIが物理的な数値だけを追い、動作の意味を理解していないために起こります。ここにVLAを導入することで、AIは「コップを運ぶ」という指示の背後にある常識(例:こぼさない、丁寧に扱う)をインターネット上の膨大な知識から理解した状態で学習に臨めます。この挙動をベースに強化学習で微調整を行うことで、効率的に学習を行うことができます。
5. まとめ:フィジカルAIにおける強化学習の立ち位置
本記事では、強化学習(RL)の基礎から、物理世界特有の課題、そしてそれを解決する最新のアプローチまでを概観しました。
強化学習は、数理モデルであるマルコフ決定過程(MDP)を土台に、報酬を最大化する方策 を自律的に見つけ出す強力な仕組みです。しかし、物理世界の実装においては、単体では「膨大な時間(試行回数)」と「意図しない挙動(報酬ハック)」という高い壁にぶつかります。
このような挙動の対処するために現在ではイミテーション学習やVLAなどが存在しています。これらをベースに、強化学習で最後のチューニングを行うのが今後のフィジカルAIの中心となっていくでしょう。




