






VLA(Vision-Language-Action)モデルは、現在フィジカルAIやロボティクスの分野で最も注目されている技術の一つです。
1. VLAモデルとは何か?
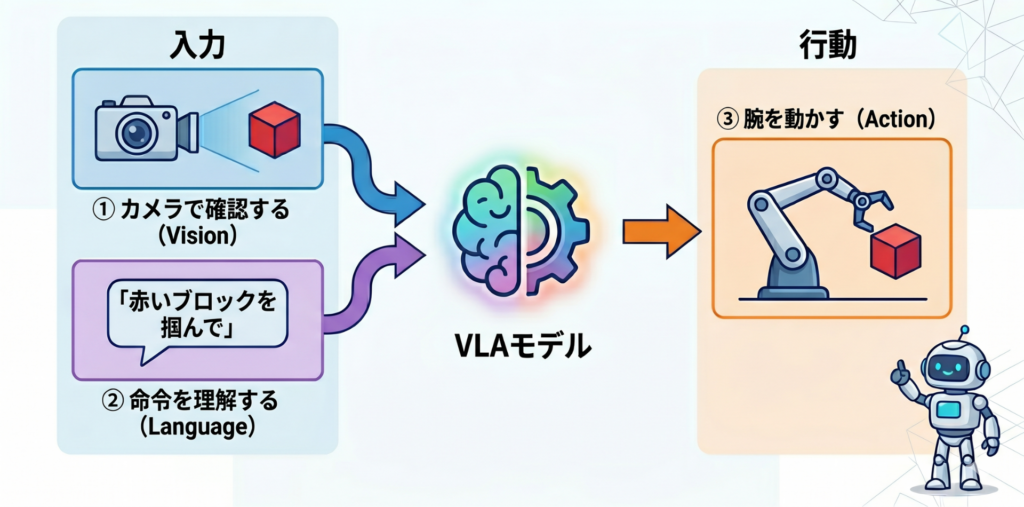
VLAモデルは、Vision(視覚)、Language(言語)、Action(行動)を一つのニューラルネットワークで統合したAIモデルです。
これまでのロボット制御は、①カメラで物を確認する(Vision)②命令を理解する(Language)③腕を動かす(Action)というプロセスを別々のプログラムで組み合わせて行っていました。VLAモデルはこれらをエンド・ツー・エンドで学習させることで、より柔軟で直感的なロボットの動作を可能にします。
2. VLAが注目されている理由
VLAモデルがこれまでのロボットAIと決定的に違う点は汎用性にあります。具体的には、以下の特徴を持っています。
2.1. 未学習のタスクでも対応できること
従来のロボットは、教えられた動作(例:赤いボールを掴む)しかできませんでした。しかし、VLAは膨大なインターネット上のデータから学習されたAIであるため、「恐竜のぬいぐるみをゴミ箱に捨てて」といった、直接訓練されていない指示に対しても、見た目と言葉の関連性から推論して実行できる能力を持っています。
2.2. 言語による高度な推論
「お腹が空いたから何か食べるものを探して」という抽象的な指示に対し、VLAは視覚情報からリンゴを認識し、掴んで手渡すという行動を選択できます。これは、VLAが言語モデルと物理的な行動を統合させているからこそ可能な行動です。
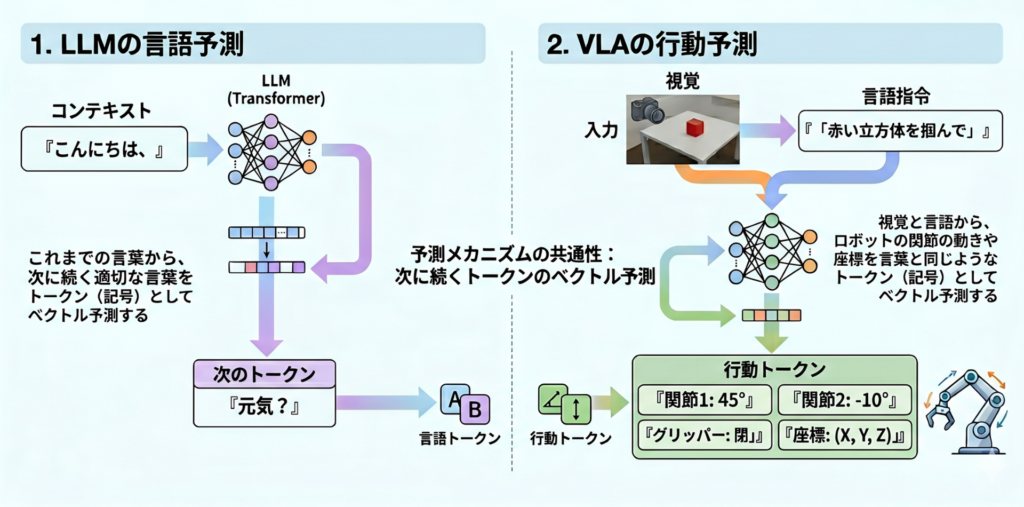
2.3. 動作のトークン化
LLMでは、次に続く言葉をトークンとしてベクトルを予測することによってチャットを可能にしています。VLAモデルの多くは、これと同じようにロボットの関節の動きや座標を言葉と同じようなトークン(記号)として扱うことで、ロボットの操作を可能にしています。
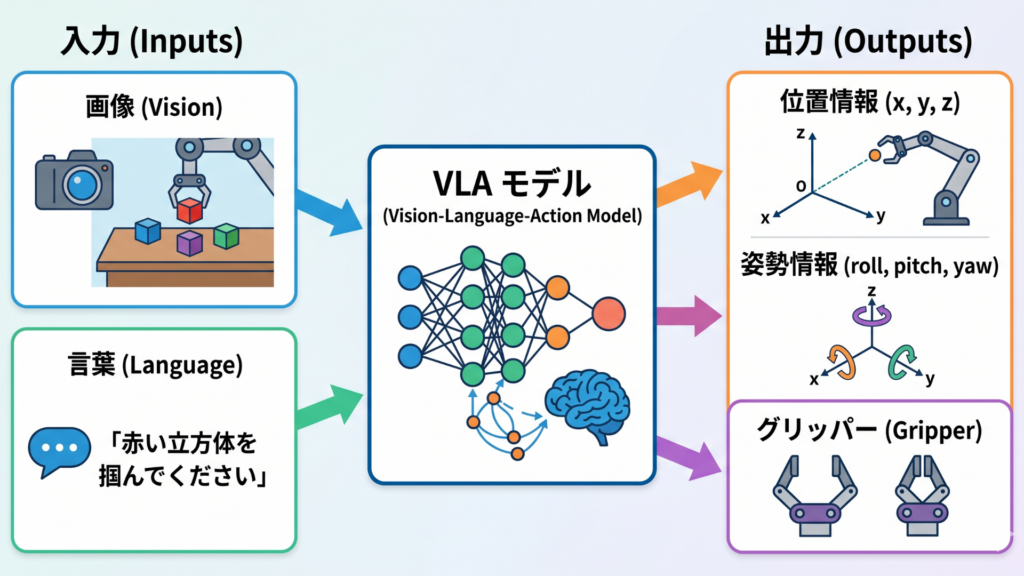
3. VLAにおける入力と出力
VLAモデルは画像と言葉を入力として受け取り、ロボットの動作を出力として出すことでロボットを操作しています。現在はVLAモデルで腕を動かすことが主流なので、今回はこれを例にして説明します。
3.1. 入力
VLAモデルへの入力は、主に以下の3つの情報を統合したものです。
- 視覚情報 (Vision): ロボットのカメラ(主に一人称視点)から得られる画像データです。通常、ViT(Vision Transformer)などのパッチ分割技術によって、AIが理解できる形式に変換されます。
- 言語指令 (Language): 「テーブルの上にある青いカップを片付けて」といった自然言語のテキストを指示として受け取ります。
- ロボットの状態 (Proprioception): 現在の腕の関節角度やグリッパーの開閉状態など、ロボット自身の「今の姿勢」の情報を受け取ります。
これらを一つのシーケンスとしてAIに入力することで、モデルは、この状況で、この指示を達成するために、自分はどうあるべきかを同時に計算します。
3.2. 出力
VLAモデルの最もユニークな点は、出力が直接的な電流値などではなく、アクション・トークンであることです。
VLAによって出力されるパラメーターは以下の通りです。
- 位置情報(): 3次元空間における手先(エンドエフェクタ)の座標移動量です。
前後・左右・上下にどれだけ動かすかを指定し、ロボットが目標物に手を伸ばすための基本データとなります。 - 姿勢情報(): 手先の向きを決定する3つの回転軸(オイラー角)です。
- (ロール): 手首を左右にひねる動き。
- (ピッチ): 手首を上下に振る動き。
- (ヨー): 手首を左右に振る(旋回)動き。
- グリッパー(開閉): 指先の開き具合を制御する数値です。通常は0(閉じる)から1(開く)の範囲で表現され、物体を掴む・離すタイミングを決定します。
この7次元の出力に対して、トークンIDをそれぞれ対応させて出力することで、ロボットを操作します。
3.3. 制御ループ
この入力と出力は一度きりではなく、非常に短いスパン(例:0.1秒ごと)で繰り返されます。
- 入力: 現在の映像と言語指示を読み込む。
- 出力: 「右に1cm動く」というトークンを出す。
- 実行: ロボットが実際に1cm動く。
- 再入力: 動いた結果、変化した視界(新しい映像)を再度読み込み、次の操作を決定する。
このループ制御により、途中で対象物が動いたり、予想外の反応が起きたりしても、柔軟に動作を修正し続けることが可能になります。
4. 代表的なVLAモデルの例
現在、この分野を牽引している主要なモデルには以下のようなものがあります。
4.1. RT-2 (Robotics Transformer 2 / Google DeepMind)
世界に衝撃を与えた、VLAの先駆けといえるモデルです。巨大な視覚言語モデル(PaLM-Eなど)をベースに、ロボットの行動データを学習させることで、「恐竜のぬいぐるみをゴミ箱に捨てて」といった高度な推論を必要とする行動を実現しました。
4.2 OpenVLA
オープンソースで公開された高性能なモデルです。70億パラメーター規模のVLMをベースにしており、特定のロボットへの追加学習(ファインチューニング)が容易なため、世界中の研究者に広く利用されています。
4.3. π0 (Pi-zero / Physical Intelligence)
フィジカルAIの実現を掲げるスタートアップであるPhysical Intelligence社が開発した汎用基盤モデルです。 単一のロボットだけでなく、アーム、ヒューマノイド、さらには洗濯機を回すといった生活家電の操作まで、異なる種類のロボットを一つのモデルで制御することを目指しています。
5. 今後の課題
非常に強力なVLAモデルですが、実用化にはまだいくつかの壁があります。
5.1. データの不足
インターネット上に溢れる膨大なテキストや画像データとは異なり、ロボットの行動データは、実際に物理的な機体を動かして収集する必要があります。
人間が遠隔操作でデータを集める手法が主流ですが、これには多大な時間とコストがかかり、LLMが成功を収めたようなインターネット規模のデータ量を確保することが極めて困難です。
この問題を解決するために、Nvidia Omniverseなどのプラットフォームを活用した、デジタルツイン空間でのシミュレーションデータの活用が急速に進んでいます。
Nvidia Omniverseについてはこの記事を参照してください。
5.2. リアルタイム性
ロボットが現実世界で安全かつスムーズに動作するためには、コンマ数秒単位での判断が求められます。
しかし、VLAモデルのベースとなる視覚言語モデル(VLM)などは、数十億〜数千億ものパラメーターを持つ巨大なネットワークであり、これらを動かすには強力なGPUリソースが必要であり、推論(計算)に時間がかかると、ロボットの動きに遅延が生じてしまいます。
6. まとめ
従来のロボットが、あらかじめ決められた動作を繰り返すだけのものであったのに対し、VLAモデルを搭載したロボットは、目で見、言葉を理解し、自ら考えて動く知能へと進化しようとしています。特に、π0のような最新モデルが洗濯物を畳んだり、複雑な家事をこなしたりする姿は、SFの世界がすぐそこまで来ていることを予感させます。




